A survey on bias and fairness in machine learning –
In the realm of artificial intelligence, machine learning holds immense promise for revolutionizing various aspects of our lives. However, alongside its potential, a critical concern has emerged: the presence of bias in machine learning algorithms. This survey delves into the intricate world of bias and fairness in machine learning, exploring its multifaceted nature, its potential consequences, and the strategies for mitigating its harmful effects.
From the seemingly innocuous data used to train algorithms to the inherent biases embedded within the algorithms themselves, this survey examines how bias can manifest in machine learning systems. We will explore real-world examples of biased algorithms, analyzing their impact on individuals, communities, and society as a whole.
This exploration will shed light on the ethical implications of biased algorithms and the urgent need for responsible development and deployment of machine learning systems that are fair, equitable, and accountable.
*
Introduction
Machine learning (ML) is transforming various aspects of our lives, from personalized recommendations to medical diagnosis. However, the increasing reliance on ML algorithms raises concerns about bias and fairness. Bias in ML algorithms can lead to discriminatory outcomes, perpetuating existing inequalities and creating new ones.This survey explores the significance of bias and fairness in machine learning, discussing the potential consequences of biased algorithms and providing examples of real-world cases where biased algorithms have led to negative outcomes.
Potential Consequences of Biased Algorithms
Biased algorithms can have significant consequences, impacting individuals, communities, and society as a whole. These consequences can be far-reaching and multifaceted, affecting various aspects of life.
- Discrimination:Biased algorithms can perpetuate and even amplify existing societal biases, leading to unfair treatment and discrimination against certain groups. For example, a biased algorithm used for loan approvals could disproportionately deny loans to individuals from specific demographic groups, perpetuating financial disparities.
- Reduced Opportunities:Biased algorithms can limit opportunities for individuals and communities, hindering their access to essential services, education, and employment. For instance, a biased algorithm used for college admissions could unfairly disadvantage applicants from underrepresented backgrounds, limiting their access to higher education.
- Erosion of Trust:Biased algorithms can erode public trust in technology and institutions, leading to distrust and skepticism towards AI systems. This can hinder the adoption of beneficial technologies and create barriers to progress.
- Social and Economic Inequality:Biased algorithms can exacerbate existing social and economic inequalities, widening the gap between different groups and hindering social mobility. For example, a biased algorithm used for hiring could perpetuate gender or racial biases, leading to unequal representation in the workforce.
Real-World Examples of Biased Algorithms
Several real-world cases illustrate the negative consequences of biased algorithms, highlighting the importance of addressing bias in ML systems.
- COMPAS:The Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) system is used in the United States to predict recidivism risk. Studies have shown that COMPAS is biased against Black defendants, assigning them higher risk scores than white defendants with similar criminal histories.
This bias has led to discriminatory sentencing practices, disproportionately affecting Black individuals.
- Amazon’s Recruiting Tool:In 2018, Amazon scrapped a recruiting tool it had developed because it was found to be biased against women. The algorithm, trained on historical data from Amazon’s workforce, learned to associate male-dominated job titles with male candidates. This bias resulted in the tool systematically discriminating against female candidates.
- Facial Recognition:Facial recognition systems have been shown to be less accurate in identifying people of color, particularly women and darker-skinned individuals. This bias can have serious consequences, leading to wrongful arrests and other forms of discrimination.
2. Types of Bias in Machine Learning

This section delves into the different types of bias that can arise in machine learning, their causes, and their potential impact on model performance and fairness. Understanding these biases is crucial for building reliable and ethical AI systems.
Data Bias
Data bias refers to systematic errors or inaccuracies in the data used to train machine learning models. These errors can stem from various sources, including:
- Sampling Bias:Occurs when the training data does not accurately represent the real-world population. For example, a model trained on a dataset primarily consisting of images of white people may struggle to accurately recognize people of color.
- Measurement Bias:Arises when the data collection process introduces systematic errors. For instance, a survey asking about income might receive biased responses due to social desirability bias.
- Label Bias:Occurs when the labels assigned to data points are inaccurate or biased. This can happen in situations where human annotators introduce their own biases, leading to skewed classifications.
Algorithmic Bias
Algorithmic bias refers to bias introduced by the algorithms themselves during model development. This bias can manifest in various ways, including:
- Feature Selection Bias:Occurs when the algorithm selects features that are correlated with a protected attribute, leading to biased predictions. For example, a loan approval algorithm that uses zip code as a feature might perpetuate existing socioeconomic disparities.
- Model Complexity Bias:Arises when the model’s complexity is not sufficient to capture the nuances of the data, leading to biased predictions for certain groups. This can happen in situations where the data is highly complex and the model is unable to learn the underlying patterns.
- Data Split Bias:Occurs when the data is split into training, validation, and test sets in a way that introduces bias. For example, if the training set contains a disproportionate number of samples from a particular group, the model may learn biased patterns.
Societal Bias
Societal bias refers to the influence of societal prejudices and stereotypes on machine learning models. This bias can be reflected in both the data and the algorithms:
- Historical Bias:Machine learning models trained on historical data may perpetuate existing societal biases. For instance, a hiring algorithm trained on historical hiring data might discriminate against women or minorities if those groups were historically underrepresented in certain roles.
- Implicit Bias:Even when explicitly avoiding protected attributes, algorithms can still pick up on implicit biases embedded in the data. For example, a language model trained on a dataset containing biased language may reproduce those biases in its output.
- Confirmation Bias:The algorithm might reinforce existing societal biases by selecting features that confirm those biases. This can lead to a self-perpetuating cycle of discrimination.
Table of Bias Types
| Bias Type | Definition | Example | Impact | Mitigation Strategies ||—|—|—|—|—|| Data Bias | Systematic errors or inaccuracies in the training data. | A loan approval algorithm trained on a dataset primarily consisting of white borrowers may struggle to accurately assess the creditworthiness of borrowers of color.
Think of a survey on bias and fairness in machine learning like trying to diagnose a car problem. You need to understand the underlying systems and how they interact to identify the root cause. Similarly, to learn how to fix cars, you need to grasp the mechanics and the principles behind them.
A good starting point for that is how to learn to fix cars. Just like understanding car mechanics helps you fix them, understanding the algorithms and data used in machine learning helps you identify and mitigate biases.
| Can lead to unfair and discriminatory outcomes. | Data collection from diverse sources, data augmentation, and data cleaning. || Algorithmic Bias | Bias introduced by the algorithms themselves during model development. | A hiring algorithm that uses zip code as a feature might perpetuate existing socioeconomic disparities.
| Can lead to biased predictions and decision-making. | Feature selection techniques, model complexity adjustments, and data split strategies. || Societal Bias | Influence of societal prejudices and stereotypes on machine learning models. | A language model trained on a dataset containing biased language may reproduce those biases in its output.
| Can perpetuate and amplify existing societal biases. | Data de-biasing techniques, fair representation in training data, and algorithmic fairness measures. |
3. Sources of Bias in Machine Learning Data
We’ve discussed the different types of bias that can creep into machine learning models. Now, let’s dive into the root causes of these biases – the data itself! The data used to train machine learning models can be a breeding ground for bias, reflecting existing inequalities and prejudices in the real world.
Data Collection Bias
This type of bias arises from how data is collected and can significantly influence the fairness and accuracy of a machine learning model.
| Source | Description | Example | Impact |
|---|---|---|---|
| Data Collection Bias | This bias arises from the way data is collected, often reflecting existing societal biases and inequalities. It can occur when data is sampled from a non-representative population, leading to an incomplete or skewed representation of the real world. | Consider a dataset used to train a loan approval model. If the data is collected primarily from affluent neighborhoods, the model might learn to favor applicants from similar backgrounds, potentially discriminating against individuals from lower-income areas. | The model may learn to perpetuate existing biases, leading to unfair or discriminatory outcomes for certain groups. In the loan approval example, this could result in individuals from lower-income areas being unfairly denied loans despite being creditworthy. |
| Sampling Bias | When the data used to train a model doesn’t accurately represent the population it’s intended to serve, it’s called sampling bias. This can occur when the data is collected from a specific subset of the population, leaving out crucial demographics or perspectives. | Imagine a facial recognition system trained primarily on images of light-skinned individuals. This could lead to lower accuracy when identifying people with darker skin tones. | The model may perform poorly for groups underrepresented in the training data, leading to inaccurate or discriminatory predictions. In the facial recognition example, this could result in misidentifications or false positives for individuals with darker skin tones. |
| Measurement Bias | Measurement bias occurs when the data collection process systematically favors certain values or outcomes over others. This can be due to faulty instruments, inaccurate measurements, or biased data labeling. | Imagine a dataset used to train a model to predict student performance. If the dataset relies on standardized test scores as a primary indicator of performance, it might unfairly disadvantage students from disadvantaged backgrounds who may not perform as well on standardized tests despite their academic abilities. | The model may make inaccurate or unfair predictions based on biased measurements, potentially leading to incorrect assessments of student performance. |
Data Representation Bias
Data representation bias occurs when the data used to train a machine learning model doesn’t accurately reflect the real-world distribution of features or characteristics.
| Source | Description | Example | Impact |
|---|---|---|---|
| Data Representation Bias | This bias arises from the way data is represented, often reflecting existing societal biases and inequalities. It can occur when the data is skewed or incomplete, leading to an incomplete or skewed representation of the real world. | Consider a dataset used to train a job recommendation system. If the data is primarily based on job applications from men, the system might learn to recommend jobs that are traditionally considered “male” roles, potentially disadvantaging women. | The model may learn to perpetuate existing biases, leading to unfair or discriminatory outcomes for certain groups. In the job recommendation example, this could result in women being unfairly excluded from opportunities in fields where they are underrepresented. |
| Label Bias | Label bias occurs when the labels used to train a machine learning model are inaccurate or reflect existing biases. This can happen when labels are assigned by humans who may have unconscious biases, or when the labeling process is flawed. | Imagine a dataset used to train a model to detect hate speech. If the dataset is labeled by humans who may have their own biases about what constitutes hate speech, the model may learn to identify certain types of language as hate speech while missing other forms. | The model may make inaccurate or biased predictions, potentially leading to the censorship of legitimate speech or the failure to identify harmful content. |
| Missing Data Bias | Missing data bias occurs when the data used to train a machine learning model is missing certain values or information, leading to an incomplete picture of the real world. This can occur when data is not collected properly, or when certain groups are underrepresented in the data. | Imagine a dataset used to train a model to predict customer churn. If the dataset is missing information about customer demographics, the model may not be able to accurately predict churn for certain groups. | The model may make inaccurate or biased predictions, potentially leading to the misidentification of customers at risk of churning. |
Data Preprocessing Bias
Data preprocessing is a crucial step in preparing data for machine learning. However, if not done carefully, it can introduce bias into the dataset.
| Source | Description | Example | Impact |
|---|---|---|---|
| Data Preprocessing Bias | This bias arises from the way data is preprocessed, often reflecting existing societal biases and inequalities. It can occur when data is cleaned, transformed, or normalized in a way that favors certain groups over others. | Consider a dataset used to train a model to predict loan defaults. If the data is preprocessed to remove outliers, it might inadvertently remove data points from individuals who have experienced financial hardship, leading to an underrepresentation of this group in the dataset. | The model may learn to make inaccurate or biased predictions, potentially leading to the misidentification of individuals at risk of defaulting on their loans. |
| Feature Engineering Bias | Feature engineering involves selecting and transforming relevant features from the raw data to improve the performance of a machine learning model. However, this process can introduce bias if it’s not done carefully. | Imagine a dataset used to train a model to predict job performance. If the dataset is preprocessed to remove features related to gender, race, or ethnicity, it might inadvertently remove valuable information that could be used to improve the model’s accuracy. | The model may make inaccurate or biased predictions, potentially leading to the misidentification of individuals with high job performance. |
| Data Normalization Bias | Data normalization is a technique used to scale data to a common range, which can be helpful for improving the performance of some machine learning models. However, normalization can also introduce bias if it’s not done carefully. | Imagine a dataset used to train a model to predict customer satisfaction. If the data is normalized using a method that favors certain groups, it might lead to biased predictions. | The model may make inaccurate or biased predictions, potentially leading to the misidentification of customers with high satisfaction levels. |
Methods for Detecting Bias in Machine Learning Models
Detecting bias in machine learning models is crucial for ensuring fairness and ethical use. Several methods can be employed to identify and mitigate bias, ranging from statistical analysis to adversarial testing.
Statistical Analysis
Statistical analysis techniques can be used to identify potential biases in the data and model predictions. These techniques can help uncover disparities in the distribution of features across different groups, which may indicate bias.
- Disparate Impact Analysis:This method assesses whether the model’s predictions have a disproportionate impact on different groups. For example, a loan approval model might have a higher rejection rate for applicants from certain demographic groups, indicating disparate impact.
- Correlation Analysis:Examining the correlation between protected attributes (e.g., race, gender) and model predictions can reveal biases. Strong correlations might suggest that the model is relying on these attributes to make decisions, even if they are not relevant to the task.
- Regression Analysis:Regression models can be used to identify the influence of different features on the model’s predictions. This can help determine whether protected attributes are disproportionately influencing the outcome.
Fairness Metrics
Fairness metrics provide quantitative measures of bias in machine learning models. These metrics assess different aspects of fairness, such as equality of opportunity, equalized odds, and demographic parity.
- Equalized Odds:This metric ensures that the model’s predictions are equally accurate for different groups, regardless of the true outcome. For example, a loan approval model should have the same accuracy in predicting loan defaults for both male and female applicants.
- Demographic Parity:This metric aims for equal representation of different groups in the model’s predictions. For instance, a job recommendation system should recommend jobs to candidates from different demographic groups at similar rates.
- Equality of Opportunity:This metric focuses on ensuring that the model provides equal opportunities for different groups to achieve positive outcomes. For example, a college admissions model should have the same probability of accepting qualified students from all backgrounds.
Adversarial Testing
Adversarial testing involves generating inputs that are designed to trick the model into making biased predictions. These inputs are crafted to exploit weaknesses in the model’s decision-making process, exposing potential biases.
- Adversarial Examples:These are carefully crafted inputs that resemble legitimate data but can cause the model to misclassify or make biased predictions. For example, a facial recognition system might misidentify a person’s race if it is trained on a dataset that is biased towards certain ethnicities.
- Adversarial Training:This technique involves training the model on both legitimate and adversarial examples to improve its robustness against bias. By exposing the model to challenging inputs, adversarial training can help reduce its susceptibility to making biased decisions.
Table of Methods for Detecting Bias
| Method | Strengths | Weaknesses | Applicability |
|---|---|---|---|
| Statistical Analysis | Provides quantitative evidence of bias | May not always capture subtle forms of bias | Applicable to various types of bias |
| Fairness Metrics | Offers specific measures of fairness | Can be difficult to choose the most appropriate metric | Applicable to specific types of bias |
| Adversarial Testing | Can expose hidden biases | Can be computationally expensive | Applicable to models with complex decision boundaries |
5. Mitigation Strategies for Bias in Machine Learning
Bias in machine learning models can lead to unfair and discriminatory outcomes, impacting individuals and society. It’s crucial to address this problem by implementing mitigation strategies to ensure fairness and ethical use of AI.
Data Preprocessing Strategies
Data preprocessing techniques aim to address bias by modifying the training data before model training.
Data Augmentation
Data augmentation involves creating synthetic data points to increase the diversity and representation of underrepresented groups in the training data. This can help mitigate bias by providing the model with a more balanced view of the data distribution.
- SMOTE (Synthetic Minority Over-sampling Technique):This technique generates synthetic data points for minority classes by interpolating between existing minority samples. It helps balance the class distribution and improve model performance on underrepresented groups.
- ADASYN (Adaptive Synthetic Sampling Approach):Similar to SMOTE, ADASYN generates synthetic data points for minority classes but adaptively focuses on generating samples in regions where minority samples are more sparsely distributed. This helps address the issue of uneven data distribution and improves model fairness.
Data augmentation can improve model fairness by addressing data imbalances and increasing the diversity of the training data. However, it’s important to note that:
- The quality of the synthetic data is crucial for effective bias mitigation. Poorly generated synthetic data can introduce noise and further exacerbate bias.
- Data augmentation techniques should be carefully chosen and implemented to avoid overfitting and introducing unwanted artifacts into the training data.
Data Cleaning
Data cleaning involves identifying and removing biased or corrupted data points from the training data. This can help improve model fairness by ensuring that the model is not learning from biased or inaccurate information.
- Outlier Detection and Removal:Outliers are data points that deviate significantly from the rest of the data. They can be caused by errors in data collection or represent genuine but rare events. Identifying and removing outliers can help reduce the impact of extreme values on model training.
- Missing Value Imputation:Missing values can occur due to various reasons, such as data corruption or incomplete data collection. Imputing missing values using appropriate techniques can help ensure that the model is not biased towards complete data points.
- Data Consistency Checks:Data consistency checks involve ensuring that the data is internally consistent and free from contradictions. This can help identify and remove biased or corrupted data points that may lead to unfair model predictions.
Data cleaning can improve model fairness by removing biased or corrupted data points. However, it’s important to note that:
- Data cleaning can be a time-consuming and complex process, especially for large datasets.
- Removing data points can lead to a loss of valuable information, especially if the removed data points represent important patterns or trends.
- It’s important to carefully consider the potential trade-offs between data cleaning and model performance.
Data Re-weighting
Data re-weighting involves assigning different weights to data points in the training data to account for imbalances in the data distribution. This can help adjust for underrepresentation or overrepresentation of specific groups and improve model fairness.
- Inverse Proportional Weighting:This technique assigns higher weights to data points from underrepresented groups and lower weights to data points from overrepresented groups. This helps balance the influence of different groups on model training.
- Over-sampling or Under-sampling:Over-sampling involves duplicating data points from underrepresented groups, while under-sampling involves removing data points from overrepresented groups. These techniques can help balance the class distribution and improve model fairness.
Data re-weighting can improve model fairness by addressing data imbalances. However, it’s important to note that:
- Re-weighting techniques can be sensitive to the choice of weights, and improper weighting can exacerbate bias.
- Re-weighting can affect the model’s ability to generalize to new data, especially if the weights are not carefully chosen.
6. Ethical Considerations in Machine Learning Fairness

The increasing prevalence of machine learning (ML) in various aspects of our lives raises critical ethical considerations. One prominent concern is the potential for bias in ML algorithms, which can lead to unfair and discriminatory outcomes. This section delves into the ethical implications of bias in ML, exploring its sources, consequences, and strategies for mitigating it.
Bias Detection and Mitigation
Bias in ML can manifest in various forms, affecting both the training data and the algorithms themselves. It’s crucial to understand how bias arises and to develop techniques for detecting and mitigating it.
- Representation Bias:This occurs when the training data underrepresents certain groups, leading to algorithms that perform poorly or unfairly for those groups. For example, a facial recognition system trained on a predominantly white dataset may struggle to accurately identify people of color.
- Algorithmic Bias:This arises from the algorithms themselves, which may encode biases present in the training data or from the design choices made during algorithm development. For instance, a loan approval algorithm trained on historical data may perpetuate existing biases against certain demographics.
Detecting bias in ML models requires careful analysis of both the training data and the model outputs.
- Data Analysis:Examining the distribution of sensitive attributes (e.g., race, gender, age) in the training data can reveal potential biases. Techniques like statistical analysis and visualization can help identify disparities and imbalances.
- Model Evaluation:Evaluating the model’s performance on different subgroups can highlight potential biases. This involves assessing metrics like accuracy, precision, and recall for various demographic groups. Techniques like fairness metrics and counterfactual analysis can help quantify and understand the extent of bias.
Mitigating bias in ML requires a multifaceted approach that addresses both the data and the algorithms.
- Data Augmentation:Increasing the diversity of the training data by adding more samples from underrepresented groups can help reduce representation bias. This can involve collecting new data or synthetically generating data points.
- Fairness-Aware Algorithms:Developing algorithms that explicitly incorporate fairness constraints can help mitigate algorithmic bias. These algorithms aim to minimize disparities in model outcomes across different groups.
- Bias Detection and Correction:Implementing techniques for detecting bias during model development and deployment allows for corrective actions. This can involve retraining the model with augmented data, adjusting the algorithm parameters, or using post-processing methods to mitigate bias in the model outputs.
Best Practices for Fair Machine Learning: A Survey On Bias And Fairness In Machine Learning
Building and deploying fair machine learning models requires a proactive and comprehensive approach. It’s not just about addressing bias at the end of the development process; it’s about incorporating fairness considerations throughout the entire machine learning lifecycle.
Fairness Considerations in the Machine Learning Lifecycle
To ensure fairness in machine learning, it’s essential to consider fairness from the very beginning of the development process and continue throughout the lifecycle.
- Data Collection and Preparation: The data used to train a machine learning model is the foundation of its performance. It’s crucial to ensure that the data is representative of the population the model will be used on and does not contain biases that could lead to unfair outcomes.
This includes:
- Identifying and addressing potential biases in the data collection process.
- Using data augmentation techniques to increase the diversity of the training data.
- Ensuring that the data is properly cleaned and preprocessed to remove irrelevant or biased information.
- Model Development and Training: During model development, it’s essential to select appropriate algorithms and training techniques that are less prone to bias. This includes:
- Choosing algorithms that are robust to biased data and can handle high-dimensional data effectively.
- Using regularization techniques to prevent overfitting and improve model generalization.
- Evaluating the model’s performance on different subgroups of the population to identify potential biases.
- Model Deployment and Monitoring: Once the model is deployed, it’s important to monitor its performance and identify any emerging biases. This includes:
- Regularly evaluating the model’s performance on different subgroups of the population.
- Implementing mechanisms to detect and mitigate bias in real-time.
- Providing transparency and explainability to users about how the model works and its potential biases.
Fairness Metrics and Evaluation, A survey on bias and fairness in machine learning
Evaluating the fairness of a machine learning model is crucial. This involves using appropriate fairness metrics to measure the model’s performance across different subgroups.
- Accuracy Parity: This metric ensures that the model achieves similar accuracy levels across different subgroups. For example, a loan approval model should have similar accuracy rates for both male and female applicants.
- Equal Opportunity: This metric focuses on ensuring that the model provides similar opportunities for different subgroups. For example, a hiring model should have similar rates of positive predictions for candidates from different backgrounds.
- Predictive Parity: This metric aims to ensure that the model makes similar predictions for individuals with similar characteristics, regardless of their group membership. For example, a credit scoring model should provide similar scores to individuals with similar credit histories, regardless of their race or gender.
Future Directions in Bias and Fairness Research
The field of bias and fairness in machine learning is rapidly evolving, with researchers continuously exploring new approaches and addressing emerging challenges. This section delves into current research trends and future directions, highlighting key areas of focus and potential breakthroughs.
Developing More Robust and Interpretable Fairness Metrics
Evaluating fairness in machine learning algorithms is crucial for ensuring equitable outcomes. Existing fairness metrics often have limitations and can be sensitive to specific data distributions. Current research focuses on developing more robust and interpretable fairness metrics that are less prone to biases and provide a more comprehensive understanding of algorithmic fairness.
For example, researchers are exploring the use of causal inference techniques to develop fairness metrics that account for the underlying causal relationships between protected attributes and outcomes.
Developing Algorithms that Are Less Susceptible to Bias
While mitigating bias in existing algorithms is essential, researchers are also actively developing algorithms that are inherently less susceptible to bias. These algorithms aim to minimize the impact of biased data by incorporating fairness constraints or using techniques that promote fairness by design.
For instance, researchers are investigating the use of adversarial learning techniques to train algorithms that are robust to biased data and can learn fair representations of data.
Addressing the Intersectionality of Bias
Real-world bias often manifests in complex and intersecting ways, involving multiple protected attributes. Research is increasingly focusing on understanding and addressing the intersectionality of bias, considering the interplay of different social groups and their experiences with discrimination.
For example, researchers are developing methods to analyze and mitigate bias in machine learning models that are trained on data with multiple protected attributes, such as race, gender, and socioeconomic status.
Developing Frameworks for Responsible AI
As machine learning algorithms become increasingly prevalent in various domains, ensuring their responsible development and deployment is paramount. Research is focusing on developing frameworks for responsible AI that address ethical considerations, fairness, and accountability in the design, development, and use of AI systems.
For example, researchers are working on developing guidelines and standards for ethical AI development, including principles for data collection, model development, and deployment.
Developing Explainable AI for Fairness
Understanding the decision-making process of machine learning algorithms is crucial for identifying and mitigating bias. Research is exploring the development of explainable AI techniques that can provide insights into how algorithms make decisions and highlight potential biases.
For example, researchers are developing methods for generating explanations for model predictions that are both accurate and understandable to humans, enabling users to identify and address potential fairness issues.
Case Studies of Bias in Machine Learning
Real-world applications of machine learning algorithms have revealed concerning instances of bias, impacting individuals and society in various domains. Examining these case studies is crucial to understand the nature, consequences, and potential solutions for addressing bias in AI. This section delves into specific examples across healthcare, finance, and criminal justice, highlighting the types of bias, their impact, and strategies for mitigation.
Healthcare: COMPAS and AI in Medical Diagnosis
The use of AI in healthcare holds immense potential for improving patient care, but biased algorithms can lead to disparities in treatment and outcomes. This section explores two prominent cases: COMPAS, a risk assessment tool used in the US criminal justice system, and the use of AI in medical diagnosis.
COMPAS
The COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) system is a risk assessment tool used in the US criminal justice system to predict the likelihood of recidivism. However, studies have shown that COMPAS exhibits racial bias, disproportionately assigning higher risk scores to Black defendants compared to white defendants with similar criminal histories.
This bias has significant implications for sentencing decisions, as judges often rely on COMPAS scores to determine bail amounts, sentencing lengths, and parole eligibility.
- A study by ProPublica found that Black defendants were twice as likely to be incorrectly labeled as high-risk compared to white defendants with similar criminal histories. This disparity can lead to longer prison sentences, harsher bail conditions, and reduced access to parole, further exacerbating racial disparities in the criminal justice system.
- The bias in COMPAS has been attributed to factors such as the training data used to develop the algorithm, which may reflect existing racial biases in the criminal justice system. Additionally, the algorithm’s reliance on subjective factors, such as criminal history and social ties, can perpetuate existing societal biases.
- Addressing bias in COMPAS requires a multifaceted approach. This includes developing algorithms with more diverse training data, implementing fairness audits to assess and mitigate bias, and prioritizing transparency and accountability in the use of the tool.
AI in Medical Diagnosis
AI is increasingly being used in medical diagnosis, with algorithms analyzing patient data to identify potential health risks and recommend treatment plans. However, biased algorithms can lead to misdiagnosis and disparities in treatment outcomes.
- For example, a study found that an AI algorithm used to diagnose skin cancer was less accurate at identifying melanoma in patients with darker skin tones. This bias can result in delayed diagnosis and potentially worse outcomes for patients with darker skin.
- The bias in AI-powered medical diagnosis can stem from several factors, including the use of training data that is not representative of the diverse patient population. Additionally, biases in the design and development of the algorithms themselves can contribute to disparities in treatment.
- Mitigating bias in AI-powered medical diagnosis requires careful attention to data representation, algorithm design, and ongoing monitoring of performance across diverse patient populations. Strategies include using diverse training data, incorporating fairness metrics into algorithm evaluation, and promoting transparency and accountability in the development and deployment of these tools.
Impact of Bias on Different Groups

The consequences of biased algorithms extend far beyond mere inaccuracies. These algorithms can disproportionately affect certain demographic groups, leading to systemic disadvantages and perpetuating existing societal inequalities. Understanding the impact of bias on different groups is crucial for mitigating its harmful effects and ensuring fairness in machine learning applications.
Algorithmic Discrimination and Its Consequences
Algorithmic discrimination occurs when a machine learning model produces biased outputs that disadvantage certain groups. This can manifest in various ways, such as:
- Unequal access to opportunities: Biased algorithms can lead to unfair decisions in areas like loan approvals, hiring, and college admissions, denying opportunities to individuals from marginalized communities. For example, a loan application algorithm trained on historical data might unfairly deny loans to individuals with lower credit scores, who may disproportionately belong to certain racial or socioeconomic groups.
- Reinforcement of existing inequalities: Biased algorithms can perpetuate existing societal inequalities by reinforcing stereotypes and discriminatory practices. For instance, a facial recognition system trained on datasets with a limited representation of certain ethnicities might struggle to accurately identify individuals from those groups, leading to potential misidentification and unfair treatment.
- Exacerbation of social divisions: Biased algorithms can contribute to social divisions by creating and reinforcing negative perceptions about certain groups. For example, a news recommendation algorithm that prioritizes content based on existing biases might expose users to a limited range of perspectives and reinforce their pre-existing beliefs.
The consequences of algorithmic discrimination can be severe, leading to:
- Economic disparities: Biased algorithms can contribute to economic disparities by denying opportunities to individuals from marginalized communities. For example, a hiring algorithm that favors candidates from specific backgrounds might perpetuate existing inequalities in the labor market.
- Social exclusion: Biased algorithms can lead to social exclusion by limiting access to resources and opportunities. For example, a healthcare algorithm that prioritizes certain groups might lead to unequal access to medical care.
- Erosion of trust: Biased algorithms can erode trust in institutions and technologies, particularly among marginalized communities who experience their negative consequences. For example, a criminal justice algorithm that disproportionately targets individuals from certain racial groups can erode trust in the legal system.
11. Legal and Regulatory Frameworks for Fairness

The development and deployment of machine learning algorithms have raised concerns about fairness and bias, prompting the emergence of legal and regulatory frameworks to address these issues. This section explores the legal and regulatory landscapes in the United States and the European Union, examining their approaches to promoting fairness in AI.
Legal and Regulatory Frameworks in the United States
The United States has a patchwork of laws and regulations that address bias in AI systems, with no single comprehensive framework. However, several existing laws and regulations have implications for fairness in AI, including:
- The Civil Rights Act of 1964: This landmark legislation prohibits discrimination based on race, color, religion, sex, or national origin. While not explicitly focused on AI, it can be applied to AI systems that perpetuate discriminatory outcomes.
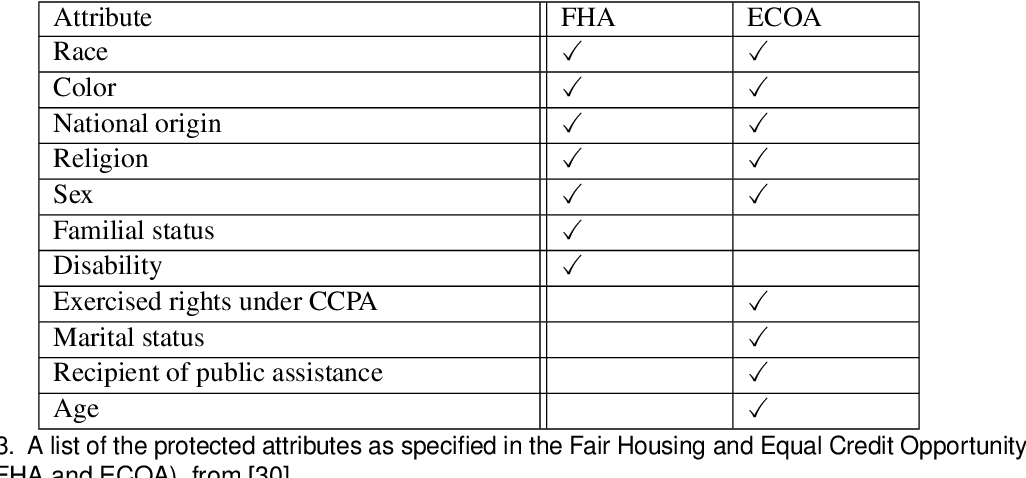
- The Fair Housing Act of 1968: This act prohibits discrimination in housing based on race, color, religion, sex, national origin, familial status, or disability. AI systems used in housing decisions, such as loan approvals or rental applications, must comply with this act.
- The Equal Credit Opportunity Act (ECOA): This act prohibits discrimination in credit lending based on race, color, religion, national origin, sex, marital status, age, or receipt of public assistance. AI systems used in credit scoring and loan approval processes must comply with ECOA.
- The Americans with Disabilities Act (ADA): This act prohibits discrimination against individuals with disabilities in employment, public accommodations, transportation, communication, and other areas. AI systems used in hiring, accessibility, or healthcare must comply with the ADA.
- The Genetic Information Nondiscrimination Act (GINA): This act prohibits discrimination based on genetic information in employment and health insurance. AI systems used in healthcare and employment decisions must comply with GINA.
These laws and regulations provide a foundation for addressing bias in AI systems by prohibiting discriminatory practices and outcomes. However, they lack specific guidance on AI-related issues, leaving room for interpretation and potential loopholes.
Key Provisions for Mitigating Bias
The legal and regulatory frameworks in the United States aim to mitigate bias in AI systems through various provisions, including:
- Prohibition of Discrimination: Laws like the Civil Rights Act and the Fair Housing Act prohibit discriminatory practices and outcomes, regardless of the technology used. This applies to AI systems that perpetuate bias based on protected characteristics.
- Transparency and Explainability: Some regulations, such as the ECOA, require lenders to provide clear explanations for credit decisions. This promotes transparency and accountability, allowing individuals to understand the rationale behind AI-driven outcomes.
- Data Privacy and Security: Laws like the Health Insurance Portability and Accountability Act (HIPAA) and the California Consumer Privacy Act (CCPA) protect sensitive data, ensuring its responsible use in AI systems. This helps prevent the perpetuation of bias through biased data.
- Algorithmic Auditing: Emerging regulations are promoting algorithmic auditing, requiring organizations to assess the fairness and accuracy of their AI systems. This can help identify and mitigate bias before deployment.
These provisions aim to create a legal framework that encourages the development and deployment of fair and unbiased AI systems.
Enforcement Mechanisms
Enforcement mechanisms for these frameworks include:
- Civil lawsuits: Individuals or groups can file lawsuits alleging discrimination based on AI systems.
- Government investigations: Regulatory agencies like the Equal Employment Opportunity Commission (EEOC) and the Department of Housing and Urban Development (HUD) can investigate allegations of discrimination involving AI systems.
- Administrative penalties: Regulatory agencies can impose fines or other penalties on organizations that violate laws and regulations related to fairness in AI.
- Industry self-regulation: Industry groups are developing best practices and guidelines to promote fairness in AI, encouraging voluntary compliance.
These mechanisms provide a framework for holding organizations accountable for the fairness of their AI systems.
Examples of Cases
Several cases highlight the application of legal frameworks to address bias in AI systems:
- COMPAS: A criminal risk assessment tool used in the US justice system was found to be biased against Black defendants. A lawsuit argued that COMPAS violated the Equal Protection Clause of the Fourteenth Amendment, highlighting the potential for legal challenges against biased AI systems.
- Facial recognition: Several lawsuits have challenged the use of facial recognition technology, alleging bias against people of color. These cases raise concerns about the potential for discriminatory outcomes and the need for regulation to ensure fairness in this technology.
These cases demonstrate the increasing scrutiny of AI systems and the potential for legal action to address bias.
Legal and Regulatory Frameworks in the European Union
The European Union has taken a more proactive approach to regulating AI, aiming to establish a comprehensive framework for fairness and ethical AI development.
- The General Data Protection Regulation (GDPR): This regulation emphasizes data protection and privacy, requiring organizations to ensure that data processing is lawful, fair, and transparent. This includes protecting individuals from discriminatory outcomes based on their personal data.
- The Artificial Intelligence Act (AI Act): This proposed legislation aims to regulate AI systems based on their risk levels, with stricter requirements for high-risk AI systems, including those used in law enforcement, recruitment, and healthcare. The AI Act includes provisions for risk assessment, transparency, and human oversight to mitigate bias.
These frameworks aim to establish a strong legal foundation for ethical and fair AI development and deployment.
Key Provisions for Mitigating Bias
The EU’s legal and regulatory frameworks include several key provisions to mitigate bias in AI systems:
- Risk Assessment: The AI Act requires organizations to conduct risk assessments for high-risk AI systems, including identifying and mitigating potential biases.
- Transparency and Explainability: Organizations must provide clear and understandable information about how their AI systems work, including their decision-making processes. This promotes accountability and helps identify potential biases.
- Human Oversight: The AI Act emphasizes the importance of human oversight in AI systems, particularly for high-risk applications. This ensures that human judgment is involved in decision-making, mitigating potential biases.
- Data Governance: The GDPR and the AI Act place strong emphasis on data governance, requiring organizations to ensure that data used in AI systems is accurate, complete, and non-discriminatory.
These provisions aim to create a robust legal framework that encourages the development and deployment of fair and unbiased AI systems.
Enforcement Mechanisms
The EU has established several enforcement mechanisms to ensure compliance with its legal and regulatory frameworks:
- Data Protection Authorities (DPAs): The GDPR empowers DPAs to investigate and enforce data protection rules, including those related to fairness in AI.
- Market Surveillance Authorities: The AI Act proposes the establishment of market surveillance authorities to oversee the development and deployment of AI systems, ensuring compliance with the law.
- Financial penalties: The GDPR and the AI Act provide for significant financial penalties for organizations that violate the regulations.
These mechanisms provide a strong framework for holding organizations accountable for the fairness of their AI systems.
Public Awareness and Education
Understanding and addressing bias in machine learning requires a collective effort, and public awareness plays a crucial role. By educating the public about the potential risks and implications of biased algorithms, we can foster a more informed and critical approach to these technologies.
Strategies for Public Engagement
It’s essential to engage the public in discussions about fairness and algorithmic accountability. This can be achieved through various strategies:
- Public Workshops and Events:Hosting workshops and events can provide a platform for interactive learning and discussion about bias in machine learning. These sessions can cover topics like the different types of bias, the impact on various groups, and mitigation strategies.
- Educational Resources and Campaigns:Creating accessible and engaging educational resources, such as infographics, videos, and online courses, can effectively disseminate information about bias in machine learning to a wider audience.
- Community Outreach and Collaboration:Engaging with diverse communities and collaborating with organizations working on social justice issues can help tailor outreach efforts and ensure that the message reaches those most impacted by biased algorithms.
- Media Engagement:Utilizing media platforms like newspapers, magazines, and social media to raise awareness about bias in machine learning can reach a large audience and spark important conversations.
Conclusion
This survey has unveiled a sobering reality: bias is pervasive in machine learning algorithms, with significant consequences for individuals, society, and various sectors. From the data used to train these algorithms to the design of the models themselves, biases can creep in and lead to discriminatory outcomes.
Key Findings and Examples
The survey has highlighted several key findings:
- Prevalence:Bias is prevalent in machine learning algorithms, impacting various domains such as healthcare, finance, and criminal justice. For example, facial recognition systems have been shown to be less accurate for people of color, potentially leading to misidentification and wrongful arrests.
- Sources:Bias can stem from various sources, including:
- Data Bias:Data used to train machine learning models often reflects existing societal biases, leading to biased outputs. For instance, datasets used for hiring algorithms may be skewed towards candidates with specific backgrounds, perpetuating existing inequalities.
- Algorithmic Bias:The design of the algorithm itself can introduce bias, particularly when using complex models that are difficult to interpret. For example, algorithms used for loan approvals might inadvertently discriminate against applicants based on their zip code, reflecting socioeconomic disparities.
- Human Bias:Human developers and researchers can unknowingly introduce biases into the development process, reflecting their own perspectives and assumptions. For example, a team developing a language model might unintentionally train it on data that perpetuates gender stereotypes.
- Impact:The impact of bias in machine learning can be profound, leading to:
- Discrimination:Biased algorithms can perpetuate existing inequalities and lead to unfair treatment of individuals based on factors like race, gender, or socioeconomic status. For instance, biased loan algorithms might deny loans to individuals in marginalized communities, perpetuating financial disparities.
- Social and Economic Inequality:The widespread use of biased algorithms can exacerbate social and economic inequalities, creating a feedback loop that reinforces existing disadvantages. For example, biased hiring algorithms might perpetuate gender disparities in the workforce.
- Erosion of Trust:Biased algorithms can erode public trust in technology and institutions, particularly among those who are disproportionately affected by bias. For example, biased facial recognition systems have led to concerns about privacy and civil liberties.
Addressing Bias and Promoting Fairness
It is imperative to address bias in machine learning to ensure the development and deployment of fair and equitable AI systems. This requires a multi-pronged approach:
- Mitigation Techniques:Developing and implementing techniques to mitigate bias in machine learning models is crucial. These techniques include:
- Data Preprocessing:Addressing biases in the data used to train models, such as removing sensitive attributes or using data augmentation techniques.
- Fairness-Aware Algorithms:Designing algorithms that explicitly incorporate fairness constraints, such as ensuring equal opportunity or disparate impact mitigation.
- Model Monitoring:Continuously monitoring machine learning models for bias and adjusting them as needed to ensure fairness over time.
- Ethical Considerations:Ethical considerations must be at the forefront of machine learning development, ensuring that algorithms are used responsibly and ethically. This includes:
- Transparency:Developing transparent algorithms that are understandable and explainable to stakeholders, allowing for accountability and trust.
- Accountability:Establishing mechanisms for holding developers and deployers of AI systems accountable for the fairness and ethical implications of their algorithms.
- User Engagement:Engaging with users and stakeholders to understand their needs and concerns, ensuring that AI systems are designed and deployed in a way that respects their values.
- Collaboration and Partnerships:Collaboration between researchers, developers, policymakers, and stakeholders is essential to foster a more inclusive and equitable AI landscape. This includes:
- Sharing Best Practices:Developing and sharing best practices for building fair and unbiased algorithms, promoting knowledge exchange and collaboration within the AI community.
- Policy Development:Working with policymakers to develop regulations and guidelines that promote fairness and ethical AI development.
- Public Awareness and Education:Raising public awareness about the importance of fairness in AI, educating the public about the potential risks and benefits of these technologies.
Answers to Common Questions
What are the potential consequences of biased algorithms?
Biased algorithms can lead to unfair outcomes, discrimination, and perpetuate existing societal inequalities. For example, biased algorithms in hiring processes could lead to discrimination against certain groups, while biased algorithms in loan approvals could limit access to financial opportunities for specific demographics.
How can I identify bias in a machine learning model?
There are various methods for detecting bias in machine learning models, including statistical analysis, fairness metrics, and adversarial testing. Statistical analysis can help identify disparities in model performance across different groups, while fairness metrics quantify the degree of bias in model predictions.
Adversarial testing involves using adversarial examples to probe the model’s vulnerability to biased inputs.
What are some strategies for mitigating bias in machine learning?
Mitigation strategies for bias in machine learning include data preprocessing techniques (e.g., data augmentation, data cleaning, data re-weighting), algorithmic adjustments (e.g., fairness-aware learning, adversarial training, regularization techniques), and fairness-aware training methods (e.g., fairness constraints, fairness metrics, fairness-aware optimization). These strategies aim to address bias at different stages of the machine learning lifecycle.
What are the ethical considerations involved in developing fair machine learning systems?
Ethical considerations in fair machine learning include ensuring transparency and accountability, addressing potential harm to individuals and communities, promoting inclusivity and equity, and fostering responsible AI development and deployment. It is crucial to consider the potential impact of algorithms on marginalized groups and to prioritize ethical values throughout the machine learning lifecycle.
What is the role of regulation in addressing bias in machine learning?
Regulation plays a crucial role in promoting fairness in machine learning by establishing guidelines, standards, and enforcement mechanisms to address bias. Regulatory frameworks can help ensure transparency, accountability, and ethical considerations in the development and deployment of AI systems. Governments and industry stakeholders are increasingly working together to develop comprehensive regulatory frameworks for fair AI.
-*
